什么是GAN
GAN是一种由生成网络和判别网络组成的深度神经网络架构。通过在生成和判别之间多次循环,两个网络相互对抗,试图胜过对方,从而训练了彼此。
生成网络
生成网络使用现有数据生成新数据,比如使用现有图像来生成新图像。生成网络的核心任务是从随机生成的由数字构成的向量(称为“潜在空间”, latent space)中生成数据(比如图像、视频、音频或文本)。在构建生成网络时需要明确该网络的目标,例如生成图像、文本、音频、视频,等等。
判别网络
判别网络试图区分真实数据和由生成网络生成的数据。对于输入的数据,判别网络需要基于事先定义的类别对其分类。这可能是多分类或二分类。通常,GAN 中进行的是二分类。
GAN中重要的概念
KL散度
KL 散度,也称相对熵,用于判定两个概率分布之间的相似度。它可以测量一个概率分布 p相对于另一个概率分布 q 的偏离。
如果 p(x)和 q(x)处处相等,则此时 KL 散度为 0,达到最小值。
由于 KL 散度具有不对称性,因此不用于测量两个概率分布之间的距离,因此也不用作距离的度量(metric)。
JS散度
JS 散度,也称信息半径(information radius, IRaD)或者平均值总偏离(total divergence to the average),是测量两个概率分布之间相似度的另一种方法。它基于 KL 散度,但具有对称性,可用于测量两个概率分布之间的距离。对 JS 散度开平方即可得到 JS 距离, 所以它是一种距离度量。
计算两个概率分布p和q之间JS散度的公式如下。
其中,$frac{p+q}{2}$是p和q的中点测度,$D_{KL}$是KL散度。
纳什均衡
博弈论中的纳什均衡描述了一种在非合作博弈中可以达到的特殊状态。其中每个参与者都试图基于对其他参与者行为的预判,选择使自己获益最多的最佳策略。最终形成的局面是,所有参与者都基于其他参与者的选择,采取了对自己来说最佳的策略,此时已经无法通过改变策略获益了。这种状态就称为纳什均衡。
目标函数
为了使生成网络生成的图像能以假乱真,应尽量提高生成网络所生成数据和真实数据之间的相似度。可使用目标函数测量这种相似度。生成网络和判别网络各有目标函数,训练过程中也分别试图最小化各自的目标函数。 GAN 最终的目标函数如下所示。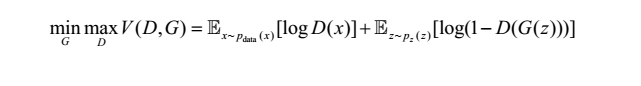
其中, D(x)是判别网络模型, G(z)是生成网络模型, p(x)是真实数据分布, p(z)是生成网络生成的数据分布, E 是期望输出。
在训练过程中, D(判别网络, discriminator)试图最大化公式的最终取值,而 G(生成网络,generator)试图最小化该值。如此训练出来的 GAN 中,生成网络和判别网络之间会达到一种平衡,此时模型即“收敛”了。这种平衡状态就是纳什均衡。训练完成之后,就得到了一个可以生成逼真图像的生成网络。
评分算法
GAN 的目标函数不是均方误差(mean-square error)或者交叉熵(cross entropy)这样确定的函数,而是在训练过程中习得的。研究者们提出了多种可以测量模型准确度的评分算法,下面介绍其中几个。
Inception分数
Inception 分数(IS)是应用最广泛的 GAN 评分算法。它使用一个在 Imagenet 上预训练过的Inception V3 网络分别提取真实图像和生成图像的特征。IS 测量生成图片的质量和多样性。计算 IS 的公式如下。
其中,$p_g$表示一个概率分布,$\chi \sim p_g$表示$\chi$是该概率分布中的一个抽样。$p(y|\chi)$是条件类别分布,$p(y)$是边缘类别分布。
计算Inception分数的步骤如下:
1)首先从模型生成的图像中抽取N个样本,记为($\chi^i$)。
2)然后使用如下公式构建边缘类别分布。
3)接着使用如下公式计算KL散度以及期望值。
$IS(G)=exp(E{\chi \sim p_g}D{KL}(p(y|\chi)||p(y)))$
4)最后计算上述结果的指数,即可得到IS。
IS 越高,说明模型质量越好。 IS 虽然是重要的测度(measure),却也存在一些问题。比如模型对于每个类别只生成一张图像,其 IS 仍然可以很高,但这样的模型缺乏多样性。
GAN的优势
1)GAN 是无监督学习方法。带标注数据需要人工制作,非常耗时。 GAN 不需要带标注数据,而可以通过无标注数据进行训练,学习数据的内在表现形式。
2)GAN 可以生成数据。 GAN 可以生成能跟真实数据媲美的数据,应用潜力巨大。 GAN 可以生成图像、文本、音频和视频等,并且和真实数据相差无几。用 GAN 生成图像可应用于市场营销、电子商务、游戏、广告等很多行业。
3)GAN 可以学习数据的概率密度分布。 GAN 可以学习数据的内在表现形式。前面提到了GAN 可以学习混乱而复杂的数据概率分布,有助于解决机器学习领域的很多问题。
4)训练后的判别网络是分类器。 GAN 训练完成之后会得到一个判别网络和一个生成网络,而判别网络可用作分类器。
训练GAN的问题
GAN 也存在一些问题。这些问题通常与训练过程有关,包括模式塌陷、内部协变量转移以及梯度消失等。
模式塌陷
模式塌陷问题指的是生成网络所生成的样本之间差异不大,有时甚至始终只生成同样的图像。有一些概率分布是多峰的(multimodal),构造十分复杂。数据可能是通过不同类型的观测得来的,因此样本中可能会暗含一些细类,每个细类下的样本之间比较相似。这样会导致数据的概率分布出现多个“峰”,每个峰对应一个细类。如果数据的概率分布是多峰的, GAN 有时就会出现模式塌陷问题,无法成功构建模型。如果生成的所有样本几乎都相同,这种情况就被称为“完全塌陷”。
解决模式坍塌问题有多种方法,例如:
1)针对不同的峰训练不同的GAN模型;
2)使用多样化的数据训练GAN。
内部协变量转移
内部协变量转移问题之所以产生,是因为神经网络输入数据的概率分布发生了变化。输入数据的概率分布改变之后,隐藏层会试图适应新的概率分布,训练速度因此放缓,需要很长时间才会收敛到全局最小值。神经网络输入数据的概率分布和该网络之前接触的数据概率分布之间差异过大是问题根源。解决方法包括批归一化以及其他归一化技术。