基于姿态估计的康复健身平台
大纲
- 系统架构
- 前端设计
- 后台架构
- 算法模块
- 2D姿态估计
- 3D姿态估计
- 动作识别
项目介绍
本项目来源是北京邮电大学的创新创业项目,主要目的是为了搭建基于人体姿态估计算法的平台,为用户在家中使用普通的2D摄像头,辅助进行健身和康复训练提供检测和指导。
系统架构

摄像头采集图片,每秒采集10帧,将视频帧(600, 400)转为base64编码格式,和用户的user-token、任务的task-id一起封装成Json对象。然后通过stomp通信协议,利用activemq消息中间件进行前端和后台之间的信息传递。前端模拟生产者发送消息,通过设定的topics发送到对应的队列Queues中。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19var client, destination, login, passcode;
url = "ws://10.103.238.165:61614";
destination = "/queue/video";
login = "admin";
passcode = "password";
client = Stomp.client(url);
'''
timer = setInterval(
function () {
ctx.drawImage(video, 0, 0, 600, 400);
var data = canvas.toDataURL('image/jpeg', 1.0); //将获取到的图像转换为base64编码
//newblob = dataURItoBlob(data);
//添加状态判断,当为OPEN时,发送消息
//var message = {};
client.send(destination, {'user-token': 123, 'task': 0x01}, data);//发送消息, 0x02 -> 0000 0010
//接收图片时间
var timestamp = new Date().getTime();
}, 100);
后台是是SpringBoot+Mybatis框架搭建,通过模拟一个消费者,应用监听器监听消息。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46(destination = "video",containerFactory = "jmsListenerContainerQueue")
public void processImage(Message message) {
// if (message instanceof BytesMessage) {
BytesMessage bytesMessage = (BytesMessage)message;
try {
// 得到一些参数:
String user_token = String.valueOf(bytesMessage.getByteProperty("user-token")); // user-token
String task = String.valueOf(bytesMessage.getByteProperty("task")); // task
String image_base64 =""; // origin image
UUID uuid= UUID.randomUUID();
String imageID = uuid.toString(); // imageID
byte[] buffer = new byte[1024*1024];
int len = 0;
while((len=bytesMessage.readBytes(buffer))!=-1){
image_base64 = new String(buffer,0,len);
}
Jedis jedis = jedisPool.getResource();
Map<String,String> imageData = new HashMap<String, String>();
imageData.put("imageID",imageID);
imageData.put("userToken",user_token);
imageData.put("taskList",task);
imageData.put("image",image_base64);
JSONObject jsonObject = JSONObject.fromObject(imageData);
// 比较task列表并分发存入对应的redis的list
int taskToDo = Integer.parseInt(task);
if((taskToDo&0x01)>0) { //pose
jedis.rpush("image_queue_to_pose_estimation", jsonObject.toString());
}
if((taskToDo&0x02)>0){ //face
jedis.rpush("image_queue_to_face_recognition", jsonObject.toString());
}
if((taskToDo&0x04)>0){ //object
jedis.rpush("image_queue_to_object_recognition", jsonObject.toString());
}
//手动释放资源,不然会因为jedisPool里面的maxActive=200的限制,只能创建200个jedis资源。
jedis.close();
} catch (JMSException e) {
e.printStackTrace();
}
}
}
后台将前端发送的Json对象解析出来,为了保证每张图片不重复,使用UUID随机生成图片ID(image_id),将image_id、user_token、task_id和image_base64放入Hashmap中,转成Json对象存入redis中,通过redis的发布/订阅模式,和服务器算法进行信息传输。算法一直运行在服务器上,订阅redis的频道channel,来监听redis中存储的消息。将消息中的Json对象解析出来后,将base_64编码的图片数据解码转变成numpy矩阵类型,送入深度学习模型,将得到的human对象的list,human对象里包含BodyParts,是每个对象的x,y坐标和置信度值。然后human对象封装成Json对象,通过发布新的通道存储在redis中,业务后台同样订阅该通道,将算法模块返回的结果通过websocket方式提供给前端展示。
消息中间件
消息中间件事一种夸进程的通信方式,这种方式使得系统之间上下游进行了逻辑和物理解耦合。使用消息中间件,在C/S或B/S模型中,请求可以由服务器端主动发起;消息中间件与上下游相对独立,不关心系统的技术架构,更适用于异构系统之间的通信和数据交互。
- ActiveMQ
ActiveMQ支持两种消息队列模型为点对点(Point To Point)模型和发布-订阅(Publisher To Subscriber)模型。其中,点对点模型以queue作为消息的承载,消息生产者发送消息到queue中,然后消费者获取消息。对于已经被消费过的信息,queue中不再存储,虽然支持多个消费者,但一个消息只能被消费一次。发布-订阅模型,以topic承载消息,生产者发布消息到topic中,订阅该topic的多个消费者能同时接收到该消息。消息的两种传送机制为推送和拉取。推送的方式有消息中间件主动将消息发送给消费者,能处理快速即时的消息,但如果消费者处理消息能力较弱,消息推送不断,则有可能造成缓冲区的溢出;拉取的方式由消费者主动向消息中间件拉取信息,会造成消息的部分延迟。 - Redis
Redis作为key-value内存型存储系统,一般作为缓存中间件使用,在某些场景下也可以作为消息中间件进行数据的缓存和传输。Redis具有基于内存的高速读写特性,支持String、List、Hash、Set、Zset五种类型的操作,支持原子性事务,还具有较为丰富的特性。将Redis作为消息中间件使用,一般利用其列表的数据结构,生产者通过Ipush来发布消息,消费者通过brpop来获取消息。此种实现方式,在Redis宕机且数据没有持久化的情况下可能造成数据的丢失,对于数据可靠性要求不是太高的场景中适用。
算法模块
2D姿态估计
CPM模型
openpose姿态估计
openpose
匈牙利算法
使用openpose获得人体的18个关键点坐标,然后输入HCN网络进行动作分类,然后使用动态时间规划进行动作匹配。
数据集:公司给的健身动作视频,每个动作是3-5s,每组动作锻炼30次,总共进行8组,每段视频都是是单一的健身指导视频。由于视频中只有单一的参与者指导动作,训练数据背景单一,估考虑采用基于骨骼关键点的行为识别。
算法流程:
1.从redis中读取图片,将base64编码转为矩阵数据
2.输入openpose算法,得到人体的18个关键点。
BODY_PARTS = { “Nose”: 0, “Neck”: 1, “RShoulder”: 2, “RElbow”:3, “RWrist”: 4, “LShoulder”: 5, “LElbow”: 6, “LWrist”: 7, “RHip”: 8, “RKnee”: 9, “RAnkle”: 10, “LHip”: 11, “LKnee”: 12, “LAnkle”: 13, “REye”: 14, “LEye”: 15, “REar”: 16, “LEar”: 17, “Background”: 18 }
3.将得到的17个关键点输入到HCN网络进行动作分类。
关键点:在训练动作分类网络时,可以对关键点信息进行数据增强。
1)归一化处理,将其他通道求平均,只保留C和V通道求数据的均值和方差,然后对每一个数据进行归一化处理。
2)时间片段选取,在150帧时间序列中选择有效的64帧
3)坐标旋转变换,随机设一个角度,对构建旋转矩阵,对关键点进行旋转变换。
CNN 模型在提取高层面信息方面能力出色,并且也已经被用于根据骨架学习空间-时间特征。这些基于 CNN 的方法可以通过将时间动态和骨架关节分别编码成行和列而将骨架序列表示成一张图像,然后就像图像分类一样将图像输入 CNN 来识别其中含有的动作。但是,在这种情况下,只有卷积核内的相邻关节才被认为是在学习共现特征。尽管感受野(receptive field)能在之后的卷积层中覆盖骨架的所有关节,但我们很难有效地从所有关节中挖掘共现特征。由于空间维度中的权重共享机制,CNN 模型无法为每个关节都学习自由的参数。这促使我们设计一个能获得所有关节的全局响应的模型,以利用不同关节之间的相关性。
着眼于人的行为动作的特点,我们将行为动作中关节点具有的共现性特性引入到网络设计中,将其作为网络参数学习的约束来优化识别性能。人的某个行为动作常常和骨架的一些特定关节点构成的集合,以及这个集合中节点的交互密切相关。如要判别是否在打电话,关节点“手腕”、“手肘”、“肩膀”和“头”的动作最为关键。不同的行为动作与之密切相关的节点集合有所不同。例如对于“走路”的行为动作,“脚腕”、“膝盖”、“臀部”等关节点构成具有判别力的节点集合。我们将这种几个关节点同时影响和决定判别的特性称为共现性(Co-occurrence)。
我们提出了一种端到端的共现特征学习框架,其使用了 CNN 来自动地从骨架序列中学习分层的共现特征。我们发现一个卷积层的输出是来自所有输入通道的全局响应。如果一个骨架的每个关节都被当作是一个通道,那么卷积层就可以轻松地学习所有关节的共现。更具体而言,我们将骨架序列表示成了一个形状帧×关节×3(最后一维作为通道)的张量。我们首先使用核大小为 n×1 的卷积层独立地为每个关节学习了点层面的特征。然后我们再将该卷积层的输出转置,以将关节的维度作为通道。在这个转置运算之后,后续的层分层地聚合来自所有关节的全局特征。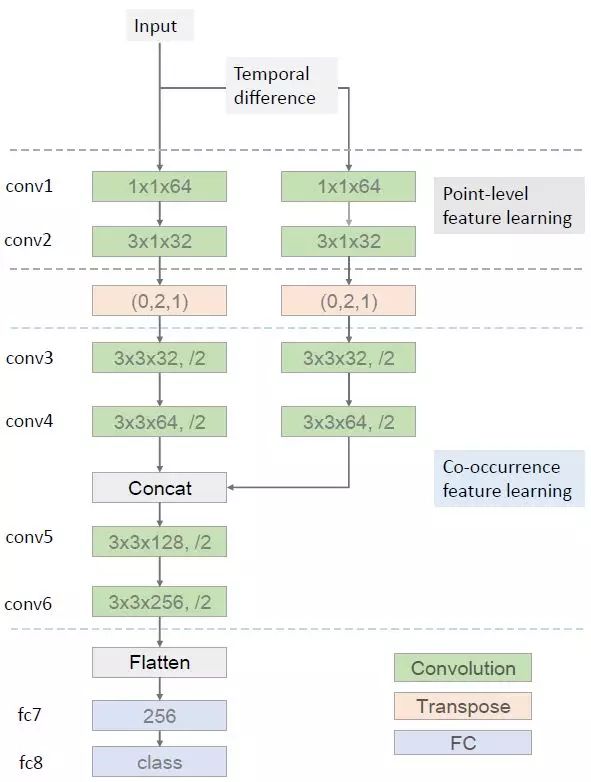
我们提出的分层式共现网络(HCN:Hierarchical Co-occurrence Network)的概况。绿色模块是卷积层,其中最后一维表示输出通道的数量。后面的「/2」表示卷积之后附带的最大池化层,步幅为 2。转置层是根据顺序参数重新排列输入张量的维度。conv1、conv5、conv6 和 fc7 之后附加了 ReLU 激活函数以引入非线性。
4.动作匹配,采用动态时间规划(DTW)算法,判断用户的运动视频和标准动作是否匹配。
DTW介绍
比较在该段时间内用户的姿态的(x,y)坐标点与标准模板的相似度进行评分。我们需要构造一个nxm的矩阵网格,矩阵元素(i, j)表示qi和cj两个点的距离d(qi, cj)(也就是序列Q的每一个点和序列C的每一个点之间的相似度,距离越小则相似度越高。)我们定义一个累加距离cumulative distances。从(0, 0)点开始匹配这两个序列Q和C,每到一个点,之前所有的点计算的距离都会累加。到达终点(n, m)后,这个累积距离就是我们上面说的最后的总的距离,也就是序列Q和C的相似度。